2011年03月31日
この記事は Qt Blog の "Improving string performance with SIMD: the revenge (fromLatin1)" を翻訳したものです。
執筆: Thiago Macieira 2011年3月23日
先週は退屈な日がありました。自分自身のモチベーションをあげるためにも、お気に入りの気晴らし方法の1つ、逆アセンブル結果を読むことにしました(決して暇なわけではないんですが)。これはコンパイラが、あるコードのセクションをどう最適化をしているのかを知るために日頃からやっていることです。これにより、何か新しいことを学んだり、改善の余地を発見することができるのです。先週は色々なことを学んだ週でした。
逆アセンブル結果を読むのはそこで何をしているかを理解している場合にのみ意味があります。アセンブリ言語を理解している必要があるのは言うまでもないことです。それ以上に、何が起きているかを理解している必要があります。ラスターペイントエンジンのような複雑なファイルは、全てが本当にぐちゃぐちゃになっているため全く意味がありません。逆に、qstring.o のような簡単なものを読むことは 昨年私がやったような 様々な成果を生み出します。
先週、私はそれまで知らなかった新しい命令 PMOVZXBW (Parallel MOVe with Zero eXtension from Byte to Word、古い "MOVZX" 命令の SIMD 版)を SSE 4.1 で発見しました。この命令は 8 個の 8 ビットの値をロードし、16 ビットにゼロ拡張し、128 ビットの SSE レジスタの1つにセーブします。なんと、この処理はまさに QString::fromLatin1 が行っていることに一致します。というわけで、私はこれを試してみることにしました。
QString::fromLatin1 を見てみると、汎用バージョンのコードは以下のようになっています。
while (len--)
*dst++ = (uchar)*src++;
これは単純な "pull-up" 処理で、簡単に並列化できます。最初に思いついたのは、8 バイトのロードに続く 16 バイトのストア(x86 では "quadword" と "double-quadword" と言います)を簡略化できないかということです。これは単純なケースでは可能です。ここで私は以前に読んだプロセッサの仕様書を思い出しました。これには条件が合えば 16 バイトのロードが可能だと書いてありました。そして実際に試した結果、x86 で SSE2 で動作する既存のコードよりも遅くなりました。
現在のコードは 8 バイトではロードしていません。そのかわり、16 バイトでロードし、(SSE 4.1 とは反対の) SSE2 で利用可能な命令で "unpack" をしています。アンパックの命令は、IA-32 インテル® アーキテクチャ ソフトウェア・デベロッパーズ・マニュアル (4-145 ページ) から抜き出した以下の図で示されるように、その値を2つのレジスタにインターリーブすることを意味します。
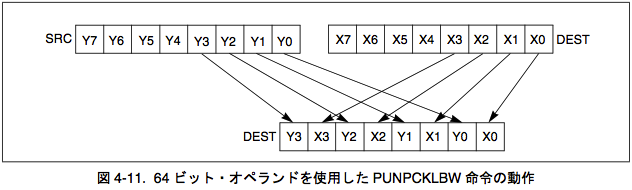
もしこの図の "Yn" が全て 0 であれば、目的のゼロ拡張が達成できます。さらに、このプロセッサには同じ処理をこのレジスタの上半分に対して行う "high unpacking" 命令もあります。つまり、 ループ毎に 16 バイトでロードし 32 バイトでストアすることが可能です。この割合は私が書いた新しい方法と同じですが、ループの中ではさらに多くのことをします。ベンチマーク結果はこれが賢い選択だということを示しており、前述の通り、最近のプロセッサでは 16 バイトの転送が1度にできるのです(ただし、ある状況下では)。さらに、ループのオーバーヘッドも重要で、"ループ展開" も効果的な改善が得られます。
ところで、誤解のないように書いておきますが、現在の SSE2 のコードは私が書いたものではなく、Benjamin Poulain が Qt 4.7 に対して行ったものです。
私は別のアプローチにも挑戦しました。8 バイトのロードの代わりに、現在のコードのように 16 バイトでロードしてはどうでしょう?これらのゼロ拡張ためにこのアンパック命令を使うのはコストが高いように思うので、これらの使用は避けたいところです。このため、16 バイトをロードし、下位の 8 バイトを 16 バイトにゼロ拡張し、ストアし、それから上位の 8 バイトを(別の SSE 4.1 の命令 PSRLDQ "packed shift right logical double-quad" で)下位にシフトするという、ゼロ拡張とストアの繰り返しを思いつきました。私が試した限りでは、アンパックを使用するコードとほぼ同じパフォーマンスの結果が得られました。別の言い方をすれば、SSE2 は広く利用可能なのに対して SSE 4.1 は Core-i7 プロセッサでしか利用できないため、あまり意味がないということです。
この時点で、私は SSE 処理の経験則に従って、アライメントを揃えたロードとストアを試すことにしました。まず、アライメントを揃える一連の前処理をし、アライメントが揃った状態でストアされるようにしました。ここでストアを選んだのはループ毎に2回のストアが必要ですが、ロードは1度で済むためです。しかし、私が昨年気づいたように、ポインタを揃える試みはそれほど効果がありません。ほとんどの文字列は非常に短い(平均で 17.82 文字)ため、前処理の複雑さがアライメントを揃えたストアの効果を相殺してしまいます。このため、アライメントを揃えないロードを今でも必要としています。実際にこの恩恵を得るためには、文字列はおそらく 16 バイト(8文字)と前処理の長さ(QString の場合は 95% の確率で7もしくは3文字)の和より遥かに長い必要があるでしょう。
それでもこれにより興味深いことが分かりました。前処理(SIMD 処理の前のデータ)からは目に見えるほどの改善結果はありませんでしたが、後処理のループ展開は効果がありました。Qt 4.7 に現在含まれる このコード でその後の(3782 行目の)ループ回数を単純に減らすことができます。このループは最大でも 15 文字分にしかならないのが分かっていたので、手動でとても長い関数にループを展開をしました。これ と他のいくつかの簡単なループでコンパイラの処理内容を減らすことにより、パフォーマンスの改善が得られました。
最後に、ARM 側についても見てみることにしました。Benjamin が Qt 4.7 向けの作業をした際、ARM ではこの改善は効果がないという結論に達していました。再度見てみたところ、私は 25% 程度のパフォーマンスの改善を得ることに成功しました。もしアセンブリコードを手で書けばもう少しは改善できるでしょう。
ARM の Neon の命令セットにはインターリーブのロード/ストア命令のとても面白い組み合わせが含まれます。これは主に画像処理用でしょう。私たちは非インターリーブのデータのロードに興味があるため、8 か 16 バイトのロード(ARM では "doubleword" と "quadword" と言います)に限られます。最初に書いたコードは 8 バイトをロード、(8 ビットを 16 ビットにゼロ拡張する)"move long unsigned"、そして 16 バイトのストアです。x86 で効果があったため、16 バイトロード、2回の VMOVL.U8 と2回のストアを試してみました。しかし、テスト用に手元にある Cortex-A8 プロセッサでは改善しませんでした(わずかに悪い結果になりました)。
最後に、Neon のロード/ストア命令には、たくさんのバイトの転送を追加することでアドレスレジスタを(自分で行う手間を省いて)更新する方法があり、このアセンブリコードを手で書いて確認してみました。効果はありましたがわずか 3% 程度でした。
今回の記事は、グラフ無しには終われません。
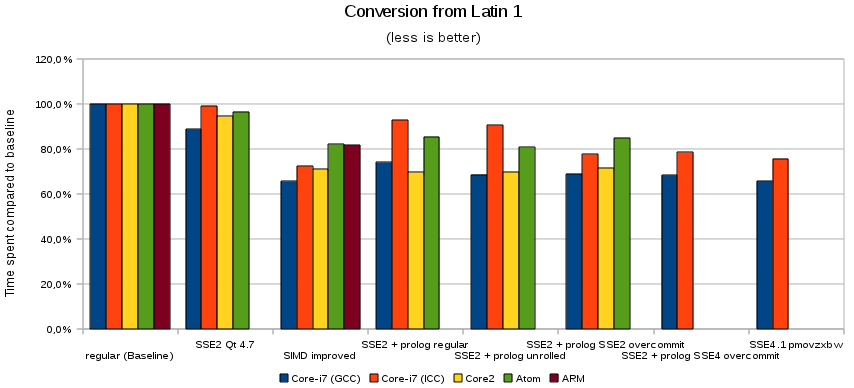
私が持っている全ての x86 CPU では(Atom でさえ) 64 ビットのコードを動かせるのですが、全てのテストは 32 ビット上で行いました。これらのマシンはそれぞれとても異なるシステムなので、マシン間の比較は意味がありません。一番左のグループを個々のマシンでの基準値とし、それに対する処理時間の比をグラフにしました。長さが短いほど速くなっていることを示します。他のグループは個々の CPU で SIMD で改善した結果を示します。私はこれらを Qt 4.8 で導入したいと思っています。
"SSE2 Qt 4.7" のグループは Qt を SSE2 以上でコンパイルした場合に得られる結果です。これは実行時ではなく、コンパイル時に決定されます。ほとんどの Linux ディストリビューションではこれは無効化されているでしょう(MeeGo では有効になってます)。
ICC の結果と GCC の結果を比べて間違った結論を出すのはやめてください。GCC では大きな改善が見られましたが、こちらのほうが良いというのは正しくありません。これは GCC の元々の基準値が高かったために起きたことです。相対的な値は非常に安定して比較できますが、絶対的な値を比較するのはそうではありません。このため、この2つを比較するのは困難です。しかしこれらの差は 10% の範囲に収まっています。
もちろん 全てのソースコード が入手可能です。 "fromLatin1_*" 関数と fromLatin1Alternatives テストをご覧ください。
次回は、fromUtf8 の処理についてです。お楽しみに。

