Over the last couple of months we have ported the text-to-speech functionality in the Qt Speech module over to Qt 6, and it will be part of the Qt 6.4 release later in 2022.
As with the Qt 5 version, Qt Speech provides application developers with a QObject subclass, QTextToSpeech, that provides an interface to the platform's speech synthesizer engine; and a value type QVoice that encapsulates voice characteristics. With those classes, applications can make themselves more accessible to users, and go beyond the screen-reader functionality of assistive technologies. Using non-visual channels to inform users about changes or events can be very useful in hands-free situations, such as turn-by-turn navigation systems. Content-focused applications like ebook readers could benefit from text-to-speech synthesis without depending on assistive technology.
The APIs in the Qt Speech module are practically unchanged, and most Qt 5 applications that use QTextToSpeech today will not have to make any code changes when moving to Qt 6.
Supported engines
We spent most of the time with reviewing, cleaning up, and improving the existing engine implementations. As with Qt 5, we will support the flite synthesizer and the speech-dispatcher on Linux. For flite, the minimum supported version will be 2.3, and we plan to support both static and dynamically linked configurations. For libspeechd we will require at least version 0.9, and the code working around shortcomings in older versions has been removed. If both engine plugins are present, then the speech-dispatcher plugin will have priority.
On Windows, the default engine is a new implementation based on the Windows Runtime APIs in the Windows.Media.SpeechSynthesis namespace. The engine uses the low-level QAudioSink API from Qt Multimedia to play the generated PCM data. We also continue to support the SAPI 5.3 based engine; the technology is somewhat outdated and doesn't have the same amount and quality of voices as the more modern WinRT engine, but it is the only engine available when building Qt with MinGW.
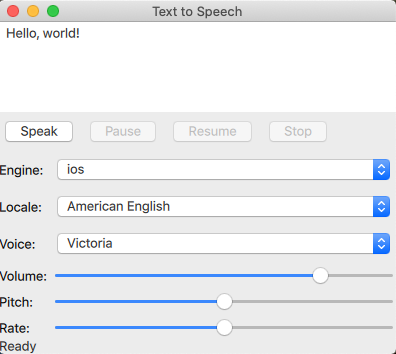
On Apple platforms we continue to support two engines. The engine currently still known as "ios" is now also available on macOS, and we will probably rename it before long. It is based on the AVSpeechSynthesizer API, whereas the engine currently still known as "macos" is based on the NSSpeechSynthesizer AppKit API. As of macOS Mojave, the AVFoundation framework API is documented to be available on macOS, but the APIs turned out to be too buggy on macOS 10.14, which we still support. The NSSpeechSynthesizer API also has bugs and limitations, but at least basic functionality works. On macOS 10.15 and up, and on any iOS platform, the AVFoundation based engine is the right choice, and perhaps we find a way to make it work on macOS 10.14 as well.
Last but not least, on Android we support the engine based on the android.speech.tts package as before.
Web Assembly support will not be included in Qt 6.4.
A note to engine implementors: We have removed the QTextToSpeechProcessor abstraction from the flite engine implementation. It was exclusively used by the flite engine, and introduced unneeded complexity only to provide threading infrastructure that could be replaced with standard signal/slot invocations. Also, we will not make any source or binary compatibility guarantees for the QTextToSpeechEngine class, as we might want to additional virtual methods in future releases (and plugins have to be built against the same Qt version as the application that loads them anyway).
Porting from Qt 5 to Qt 6
As of now, the port is functionally equivalent to the Qt 5 version, with some minor additions and changes:
QVoice is now a modern, movable C++ type. It has gotten a new locale() property which informs callers about the language that the voice is designed to speak, and it supports QDataStream operators. As in Qt 5, a QVoice can only be created by the text-to-speech engine. Applications will have to make sure that a voice loaded from a data stream is suitable for the engine that it will be set on (perhaps by saving and loading the engine name as well).
In the QTextToSpeech class, the API is practically unchanged. Call the say() function to synthesize speech for a piece of text. The speech will then be played on the default audio output device. pause(), resume(), and stop() work like before and don't need any further introduction. Properties like pitch, rate, and volume can be configured as before, and on most platforms will only impact the next call to say().
Qt 6.4 feature freeze is still a few weeks away, and we think that we can add at least one new feature from the list of suggestions in JIRA to Qt Speech: more engine-specific configure options.
On some platforms, we play the generated audio ourselves via Qt Multimedia, so we can make the audio output device configurable (QTBUG-63677). On Android, multiple speech synthesizers might be present, and we want to make that configurable as well (QTBUG-66033). At time of writing, the API for this is proposed and up for review in https://codereview.qt-project.org/c/qt/qtspeech/+/406229.
QML API
Speech synthesising is now fully usable from QML via the TextToSpeech and Voice types. Import QtSpeech.TextToSpeech to use those types in a Qt Quick application. Voice attributes are accessible directly from QML. A new QML-only example is included that does the exact same thing as the old C++-with-Widgets example.
Beyond Qt 6.4
We are focusing on completing the work for Qt 6.4 in time for the feature freeze. But we have a few ideas about more features for future releases, and we'd like to hear from you about these ideas:
Enqueueing of utterances
Today, QTextToSpeech::say() stops any ongoing utterance, and then proceeds with synthesizing the new text. We would like to see if we can make calls to say() line up new utterances so that a continuous audio stream is produced without the application having to orchestrate the calls. Several engines support this natively, and for those that don't this natively it is conceptually easy to implement on a higher level. However, we would then also like to add an API that allows applications to line up blocks of text with modified speech parameters (voice, pitch, rate etc), and applications might want to follow the speaking progress. So this requires a bit of design.
Detailed progress report
Some engines provide meta-data and callback infrastructure that reports which words are being spoken at a given time. Exposing update information on this level through signals would allow applications to better synchronize UI with speech output. From an API design perspective this goes hand-in-hand with queuing up utterances and updating progress on that level.
SSML support
SSML is a standardized XML format that allows content providers to annotate text with information for speech synthesizer engines. For example, slowing down certain phrases, changing the pitch, or controlling whether "10" is pronounced as "ten" or as "one zero". Alias tags can be used to make sure that a speech synthesizer pronounces "Qt" like it should be! Several engines support SSML input, although the supported subset varies from engine to engine. Some of the tags could be simulated by QTextToSpeech (which then again requires that we can line up utterances with different configurations). At the least we can strip away unsupported XML tags so that applications don't have to worry about a character-by-character rendition of XML to their users.
Access to PCM data
Both the flite and the WinRT engines synthesise text into a stream of PCM data that we have to pass to an audio device using Qt Multimedia. Android's UtteranceProgressListener interface makes chunks of audio data available through a callback. The AVFoundation API has a similar approach. So for several of the supported engines we might be able to give applications access to the PCM data for further processing, which might open up additional use cases.
We might also add support for more engines, in particular one for Web Assembly; flite has been ported to web assembly, but that might not be the optimal solution. And last but not least: support for speech recognition would be a great addition to the module!
Let us know how you are using Qt Speech today, which of the features you would like us to prioritise, and what other ideas you have about this module!


