Jan 18, 2022
The Numbers: Performance benefits of the new Qt Quick Compiler
In my previous post, the history and general architecture of the new Qt Quick Compiler technology was explained. As promised there, the performance numbers are presented in this post.
Along with qmlsc we've created a number of benchmarks to measure its impact. Note that classical JavaScript benchmarks like v8bench won't get us very far because those mainly exercise the aspects of JavaScript qmlsc does not intend to optimize.
The following results are produced with three modes of operation. All of the measurements were done on the current dev branch at the time of writing, which should be close enough to what we will release as Qt 6.3. There can be differences, though.
- In
plainmode, a QML file is loaded from the host file system, circumventing any caching or pre-compilation. It has to be compiled at run time and only byte code is available. This byte code is then run through the JIT compiler. - In
qmlcachegenmode,qmlcachegenis utilized to compile the file ahead of time.qmlcachegenin Qt 6.3 will be able to compile to C++, in indirect mode. It cannot directly access your C++ classes, but has to utilize the lookup infrastructure in QtQml to access values. - In
qmlscmode,qmlscis utilized to compile the file ahead of time, with the--staticand--directoptions. Code generated byqmlscin--directmode does access your C++ classes directly, expecting to be able to#includetheir headers.--staticmeans that it expects no properties to be shadowed. This is a slight deviation from the usual QML semantics, but allows for more bindings to be compiled.
As mentioned in the previous post, qmlcachegen is available with all versions of Qt starting from Qt 5.8. Starting with Qt 6.3 alpha, it also provides the new compiler functionality and generates C++ code. qmlsc will implement "Qt Quick Compiler Extensions" as mentioned here. It is now available for commercial customers of "Qt for Device Creation" and "Qt for Device Creation Enterprise". The first Technology Preview release of qmlsc was already in Qt 6.2.1 in "Qt for Device Creation". "Qt Quick Compiler Extensions" (containing qmlsc) will also be available for general application development starting latest with the Qt 6.3.0 release. Further details around this will be announced some time soon.
All the measurements below were taken with the Qt 6.3 branch at the time of writing. This includes a qmlcachegen that compiles to C++ in indirect mode.
Real-world bindings
First, let's look at some examples of somewhat realistic bindings that exercise a number of value access patterns and arithmetics, adapted from the QmlBench project.
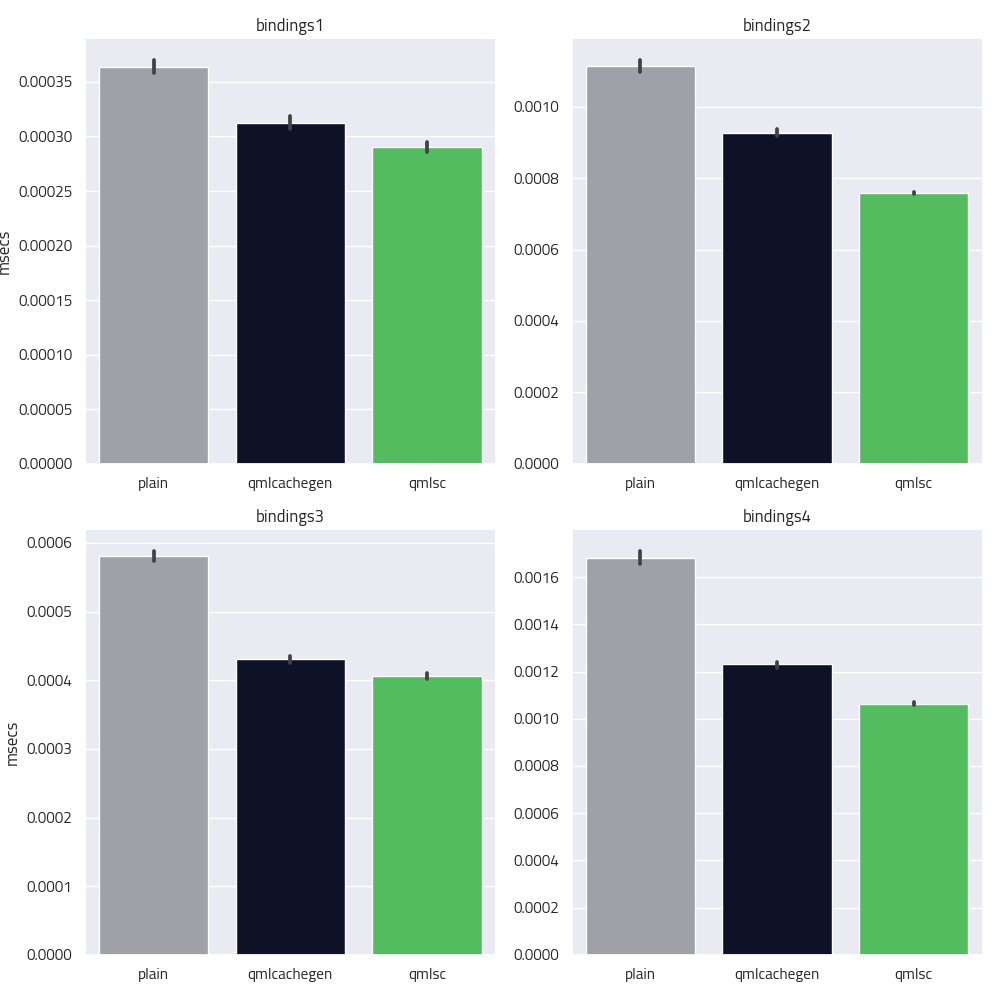
We repeated trigger re-evaluation of a binding by manipulating one of its dependencies from C++ and then measure the time it takes to re-evaluate using QBENCHMARK. The bindings are as follows:
bindings1
Item {
id: root
property int dynamicWidth: 10
Rectangle { height: root.dynamicWidth + (5 * 3) - 8 + (root.dynamicWidth / 10) }
}
bindings2
Item {
id: root
property int dynamicWidth: 100
property int dynamicHeight: rect1.height + rect2.height
Rectangle {
id: rect1
width: root.dynamicWidth + 20
height: width + (5 * 3) - 8 + (width / 9)
}
Rectangle {
id: rect2
width: rect1.width - 50
height: width + (5 * 4) - 6 + (width / 3)
}
}
bindings3
Item {
id: root
property int dynamicWidth: 10
property int widthSignaledProperty: 20
Rectangle { height: root.dynamicWidth + (5 * 3) - 8 + (root.dynamicWidth / 10) }
onDynamicWidthChanged: widthSignaledProperty = dynamicWidth + (20 / 4) + 7 - 1
}
bindings4
Item {
id: root
property int dynamicWidth: 100
property int dynamicHeight: rect1.height + rect2.height
property int widthSignaledProperty: 10
property int heightSignaledProperty: 10
Rectangle {
id: rect1
width: root.dynamicWidth + 20
height: width + (5 * 3) - 8 + (width / 9)
}
Rectangle {
id: rect2
width: rect1.width - 50
height: width + (5 * 4) - 6 + (width / 3)
}
onDynamicWidthChanged: widthSignaledProperty = widthSignaledProperty + (6 * 5) - 2
onDynamicHeightChanged: heightSignaledProperty = widthSignaledProperty + heightSignaledProperty + (5 * 3) - 7
}
We can see that all of those bindings exhibit a substantial speedup when compiled to C++, and another boost when compiled in direct mode with qmlsc.
Micro benchmarks
As noted above, those bindings are composed of a number of different operations. In the next step we examine some common operations in isolation in order to see where the AOT-compiled code saves most time. Let's first look at different kinds of value access.
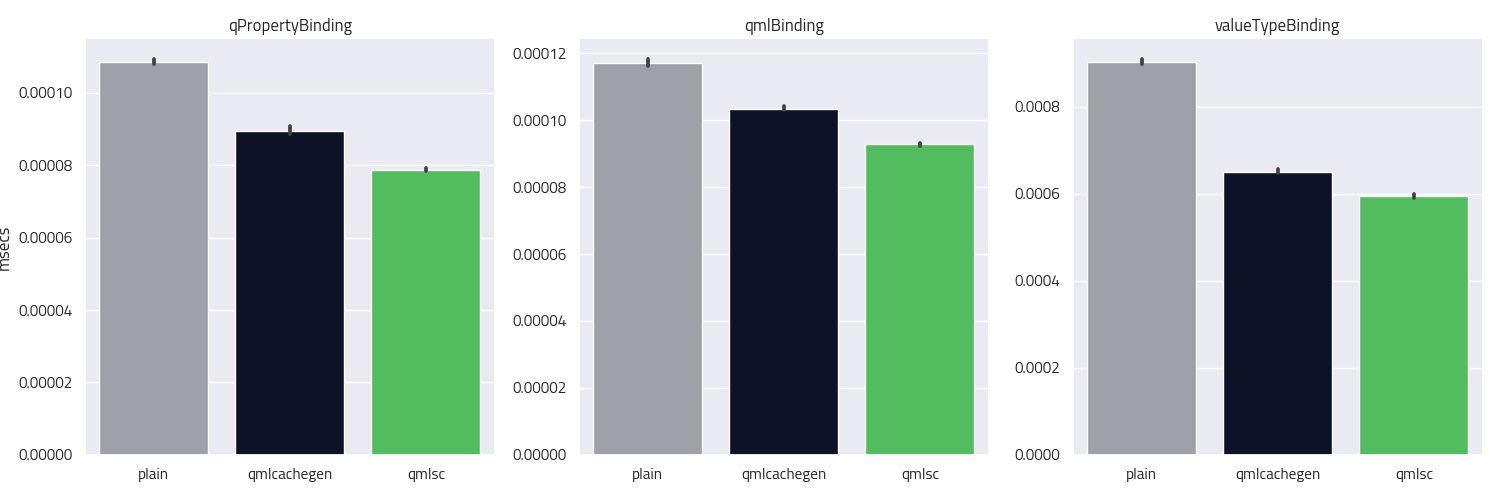
Each of these just profiles one binding a: b where the binding expression just reads one value. Here, we compare three types of access:
- QProperty bindings are bindings on members of type QProperty, where the bindings expression accesses another QProperty. These are particularly easy to optimize for
qmlscbecause it only has to read the QProperty. The QProperty dependency mechanism takes care of the house keeping. For other bindings, we have to capture the property being read so that the dependency is registered. - QML bindings are bindings where we cannot apply the QProperty optimization because one side of the binding is not a QProperty. Here we use the classical QML approach of capturing.
- Value type bindings are bindings to and from members of value types. These require some specialized lookups. The test here exercises two bindings, one that reads the
xproperty of a member of typerect, and one that writes it.
Again, we can see a consistent performance increase when using qmlcachegen, and another one when using qmlsc.
Enumerations
Another area of interest is access to enumeration values. As enumeration values have to be qualified in QML, the QML engine has to do a lookup on the surrounding type of the enumeration in order to figure out which enumeration is meant. If we compile ahead of time, we can determine this statically. This is what you can see in the following result.
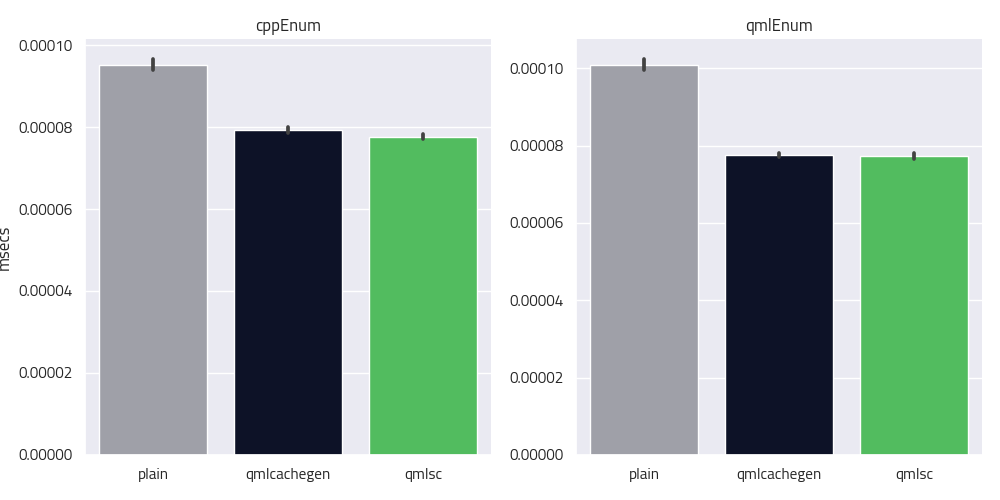
Here, we repeatedly call a JavaScript function which returns an enumeration value. We do this once with an enumeration defined in C++ and once with an enumeration defined in QML. We see that the compiled code is a lot faster than the JIT.
Storing values
Finally, we might also write values procedurally in QML. While you should avoid this where possible, we often see cases where it is not easily avoided. qmlcachegen and qmlsc can generate C++ code for such access. Here we exercise two different ways of storing a value:
- referencing the target object by id:
onXChanged: root.y = x - storing into the current scope:
onInputChanged: output = input

Again, we observe that the compiled code is faster than the JIT.
Conclusion
These numbers are to be taken with a grain of salt. The code they are produced from is not finalized, yet. However, we can already see that the compilation of QML script code to C++ promises great performance benefits. We are always happy to hear about your experience with Qt. As these compilers are fairly new, there probably still are some bugs in them. Please do report those at our bug tracker when you find them. Further improvements to qmlsc and qmltc are planned for the upcoming Qt releases. Stay tuned.


