2025年02月1日
大規模言語モデル (LLM) には、QMLコーディングのスキルレベルに差があります。この記事では、開発者を支援する上で最適なLLMはどれかについて説明します。
Qtでは、製品開発ライフサイクル全体を通じてお客様をサポートすることを使命としています。生成AIが普及している今日の世界では、お客様が希望するLLMに接続できるようにする必要があります。Qt AI Assistantは、このような柔軟性を念頭に置いて設計されています。さらに、QMLプログラミングに適したLLMをお客様が選択できるよう支援したいと考えています。そのため、LLMのQMLコーディング性能を測定するためのさまざまなコーディングベンチマークを作成しました。
QML100FIM ベンチマークの開発
OpenAI が開発したよく使われているコーディングベンチマークである HumanEval コーディングベンチマークをご存知かもしれません。 HumanEval は Python 言語のプログラミング課題のみで構成されています。 他のコード生成ベンチマーク、例えば MBPP などは、生成された QML コードの品質を測定する上であまり役立ちません。 そのため、我々は QML コーディングスキルを比較するためのベンチマークをまとめました。 より具体的には、いくつかのコーディングベンチマークを作成することにしました。1つのベンチマークは、人間の言語による指示に基づいてコードを記述する能力を測定するためのQML100ベンチマークです。もう1つのベンチマークは、fill-in-the-middle方式で生成されたコードを評価するためのQML100FIMベンチマークです。
QML100FIMベンチマークについて詳しく見てみましょう。
QML100FIMは何を測定しますか?
QML100FIMは、Fill-In-the-Middle (FIM)方式を使用してコード補完を測定することを目的としています。FIMとは、LLMが接頭辞と接尾辞とともにコード生成リクエストを受け取ることを意味します。接頭辞は、コードエディタのカーソル位置より前のコードで構成されます。接尾辞には、カーソルより後のコードが含まれます。LLMの仕事は、接頭辞と接尾辞の間のどこにコードを挿入するのが最適かを推測することです。 開発者がコードの最後に達している可能性もあるため、接尾辞は必須ではありません。 したがって、QML100FIMは接頭辞を持つタスクで構成され、一部には接尾辞もあります。
HumanEvalには164のコーディングタスクがあります。 我々は100のコーディングタスクを目指しました。 最も一般的なベンチマークの1つよりも少ないのはなぜでしょうか?HumanEvalのテストは、正解または不正解の回答からなるタスクで構成されているため自動化が容易ですが、UIコントロールのコードの採点については、単純なものではありません。QMLコードはコンパイルでき、ランタイムエラーがない場合でも、意味をなさない場合があります。例えば、MouseAreaがTextFieldの上にある場合、TextFieldの本来の機能を妨げる可能性がある一方で、ホバーイベントの認識は可能になる場合があります。したがって、最終的には、QMLリンターと手動でコード生成結果をレビューしています。
QML100FIMにはどのようなコーディングタスクが含まれていますか?
QML100FIMには、主に2つの側面をカバーするコーディングタスクが含まれています。 ボタン、スライダー、スピンボックス、入力フィールド、マウス操作、シグナル、メソッド、アニメーション、バリデーター、ダイアログなど、多種多様なQt Quickコントロールをカバーするタスクが含まれています。 さらに、マウスオーバー時のツールチップの追加や、テキスト入力の必須入力項目としてのマーク付けなど、一般的なコーディング上の課題を代表するさまざまなタスクも含まれています。
これらのタスクでは、LLMに未完成の単語、行、関数、オブジェクトを完成させることが求められます。また、LLMが接頭辞のコメントを理解する必要があるタスクも含まれています(// 単語の最初の文字を大文字にします)。これらのタスクでは、一般的なロジックを理解する能力がチェックされます。例えば、2番目のテキスト入力フィールドが、1番目の名前を入力するよう求めているが、実際には苗字を入力するよう求めるべきである、といった場合や、ハート形の右側にパスを描画する必要がある場合などです。オブジェクトの後に正しい括弧を追加したり、欠落しているQMLライブラリのインポートを挿入するといったタスクも含まれています。
QML100FIMは現在、2D UIの作成に重点を置いています。テスト対象のQMLライブラリには、QtQuick、コントロール、ダイアログ、レイアウト、図形、グラフ、およびエフェクトが含まれます。ライブラリのマルチメディア、PDF、位置、位置、またはQuick3Dはテスト対象ではありません。
コード補完が成功したとみなされるのはどのような場合でしょうか?
生成されたコードをテストし、Qt Creator における Qt 6.8 リリースへの準拠を確認しました。qmllint によって特定されたエラーが含まれていないこと、また、意味をなしていることが必要です。オブジェクトや QML アプリを完成させるために閉じ括弧を追加できない場合があり、これはすべての LLM が課題を抱えている問題ですが、程度には差があります。
ベンチマークされたLLMはどれですか?
すべての大規模言語モデルがFIMコード生成をサポートしているわけではありません。事前学習データとモデルアーキテクチャがFIMコード生成をサポートしている必要があります。例えば、Llama 3.3 70Bは英語のプロンプトに基づいてQMLコードをうまく作成できますが、FIMコード補完はサポートしていません。
比較対象として最初に選んだLLMでは、クラウドのサブスクリプションで商業的に提供されている(OpenAIとAnthropic)か、プライベートクラウドまたはローカルでロイヤリティフリーで実行できる(Meta CodeLlama 13B)最も一般的なLLMをカバーしたいと考えました。また、コードを生成しているLLMが不明であっても、CursorやGitHub Copilotなどのエンドツーエンドのコーディングアシスタントをテストすることにしました。DeepSeek Coder V2などの最新参入者の一部や、よりローカルで実行されるモデルを比較するには、まだやるべきことが残っていますが、それはまた別の機会に。
QML コード補完に最適な LLM は何ですか?
自己ホスティングに最適なロイヤリティフリーの LLM は CodeLlama 13B-QML です。商用ホスティングの LLM としては、Anthropic の Claude 3.5 Sonnet が最適です。
FIM コード補完の結果は以下の通りです。
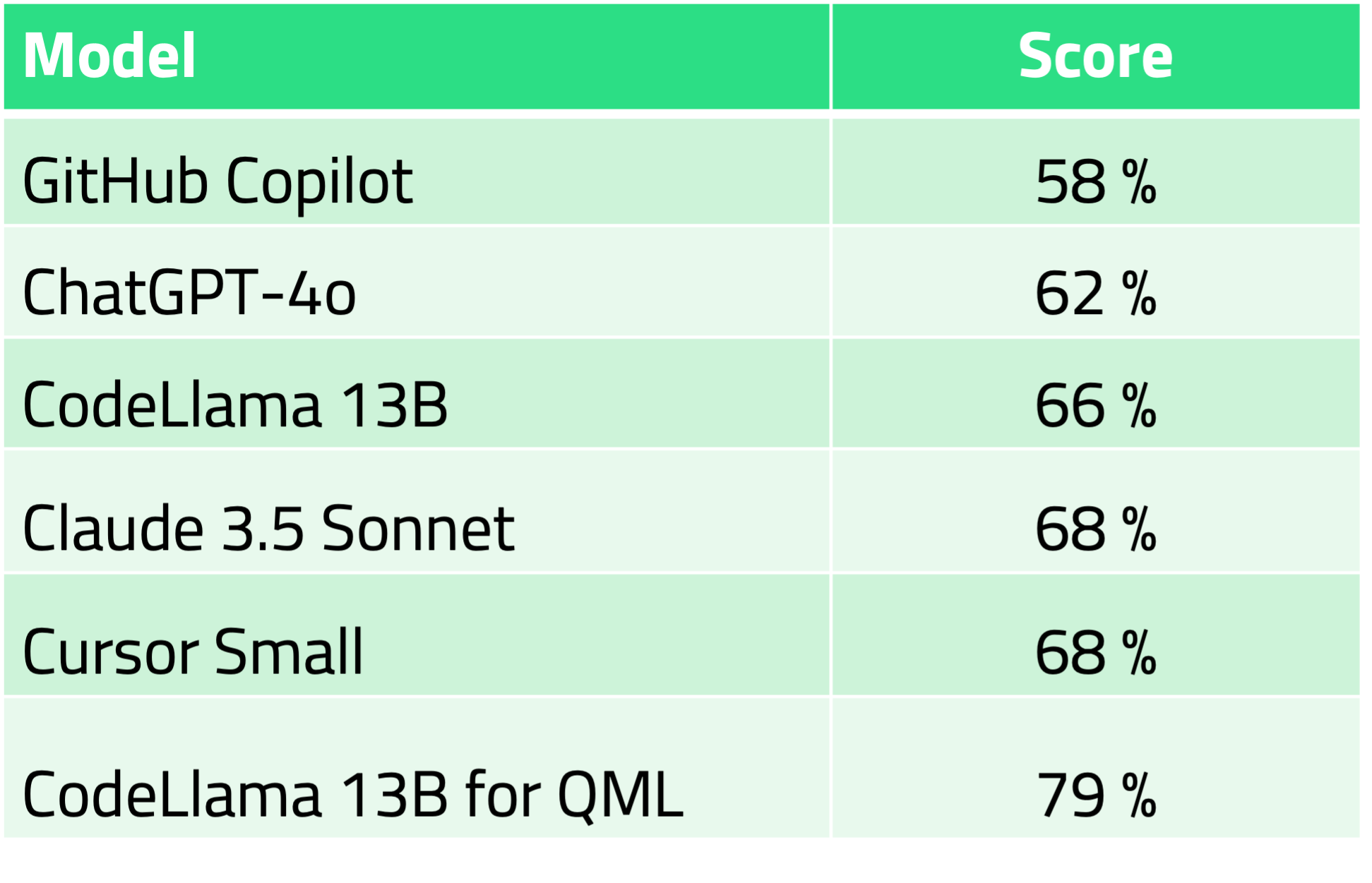
注目すべきは、CursorのQMLコード補完のパフォーマンスです。このベンチマークでは、CursorのLLM設定でCursor Small LLM以外のLLMはすべて無効にしました。驚くべきことに、ベンチマークスコアはClaude 3.5 Sonnet LLMのスコアと同じでした。明示的にそうしないよう設定しているにもかかわらず、Cursorがコード(およびIP)をAnthropicにルーティングしているのでしょうか?私たちは知りません。少なくとも、セキュリティに関するドキュメントでは、そうする権利を保持しているようです。
まとめ
ビジネスにLLMを選択することは決して容易ではありません。 展開モデル(ローカル、サードパーティのクラウド、プライベートクラウド)に関する疑問があります。 知的財産権の保護と微調整の機会を考慮する必要があります。 推論時間(コードの提案を得るのにかかる時間)を考慮する必要があります。 最終的には、コーディングのパフォーマンスが常に意思決定において重要な役割を果たすべきです。
プライベートクラウドでLLMを実行できるのであれば、CodeLlama-13B-QMLが最良の選択です。このモデルは、Hugging Faceから自己ホスティング用にロイヤリティフリーで入手できます。商用サードパーティクラウドサービスをご希望の場合は、現在、Qt AI Assistant付きのClaude 3.5 Sonnetをお勧めしています。
(2025年1月31日更新:CodeLlama-13B-QMLの結果を追加し、結論を修正)


