The code that this blog post is based on is work in progress, with various commits under review in the allocator topic. A big thank you goes out to Eddy, Marc, Fabian, Lars, and Simon for the support! Note that the code makes use of various C++17 features.
A few months ago I was working on a fix for how QHostInfo sends results to the caller, which led me further to a small optimization of how we allocate memory for the arguments in QMetaCallEvent. We use objects of that type in queued signal/slot connections, and spending some time in that code reminded me how in Qt we have a pattern of allocating rather small, short-lived objects on the heap, sometimes rather frequently, and also in performance critical code paths. I was also inspired by Jedrzej's investigations into QObject and QObjectPrivate allocations in his "fast pimpl" proof-of-concept implementation.
So I started wondering whether we could allocate QEvent instances from a dedicated memory pool, using a specialized allocator.
Some Statistics
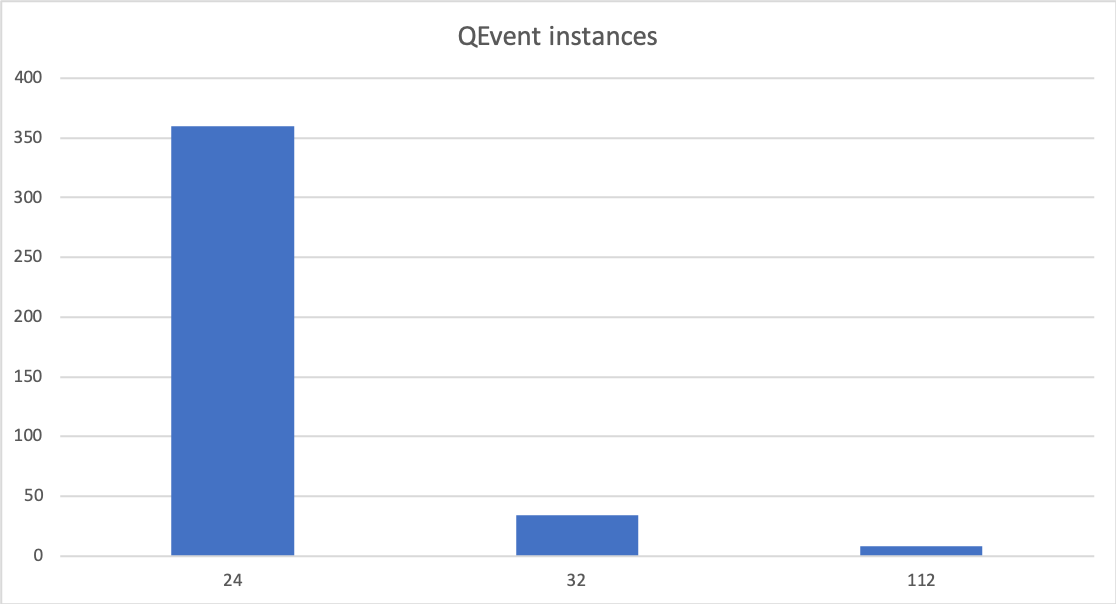
Reimplementing QEvent::operator new(size_t) and using a QHash as a histogram data-structure shows that most QEvent instances in a small Qt application are only 24 bytes large:
using HistogramHash = QHash<size_t, int>;
Q_GLOBAL_STATIC(HistogramHash, histogram);
void *QEvent::operator new(std::size_t size) noexcept
{
++(*histogram())[size];
qDebug() << "QEvent:" << *histogram();
return ::operator new(size);
}
Doing the same for QObject gives us a wider spread, but also here, the majority of instances is small, with 16 bytes being by far the most common size.
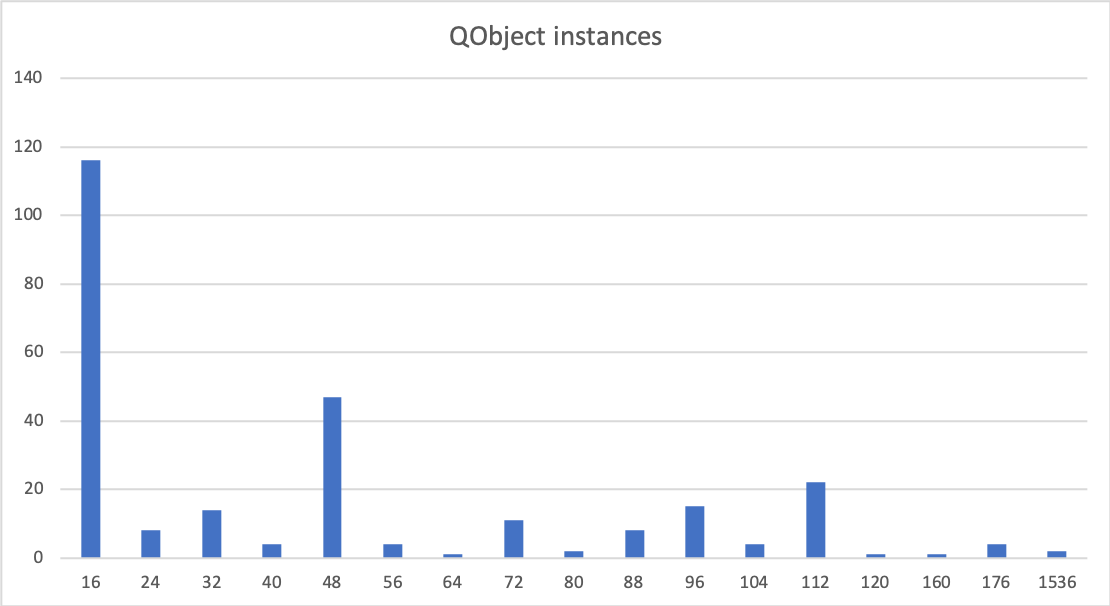
This is no surprise; a QObject instance has a virtual function table, and the d-pointer for the QObjectPrivate where all the real data lives. QObject subclasses use QObjectPrivate subclasses for their private data, and pass those private instances to QObject for storage.
So, both QEvent and QObject instances are rather small, and even an example application allocates a whole bunch of them. How hard would it be to implement a memory allocator that is optimized for these use-cases?
General purpose vs specialized allocators
The default, global C++ operator new allocates memory using malloc(). malloc() is a general purpose allocator that needs to work well for all sizes from a few bytes to several gigabyte, so it comes with a bit of book-keeping overhead for each allocation. There are various malloc() implementations, and some of those do a truly amazing job in optimizing for small object allocations and other frequent use cases. However, they are still general purpose allocators, so they have to make decisions at runtime that a specialized allocator perhaps wouldn't have to make.
Specialized allocators are typically used in situations where data structures have to be very dynamically allocated, and where creation and destruction of data needs to be highly performant. An application domain where small, short-lived objects are frequently created and destroyed are games: projectiles in a first-person shooter are one example. Other domains are scene-graphs in rendering engines, parsers that build an AST, hash-tables. In all of those cases we often know pretty well in advance what kind of memory allocations we will need to make, and we also would very much like to cut a few CPU cycles.
Another reason why a custom allocator can be valuable is that some platforms we might care about do not come with a memory management unit. As recently announced, Qt now runs on micro-controllers, and those units often don't have a MMU. In such environments, memory fragmentation as the result of frequent, small allocations can quickly become a significant issue.
By preallocating memory and managing that pool in a way optimised for the relevant usage patterns, a specialised allocator can safe a lot of overhead and kernel roundtrips. Memory fragmentation issues will at the very least be limited to that pool of memory, and are less likely to impact the entire system.
Basic data structures
Our pool allocator should give us fast allocation and deallocation for objects of different, but generally small sizes that we know about at compile time. The allocator should operate on a pool of memory large enough to only require very infrequent roundtrips to the kernel. Allocations and deallocations need to be possible in random order.
A fast data structure for managing our free chunks of memory with no overhead is an in-place stack: a preallocated page of memory is divided into equal-sized chunks, each in a node that points to the previous chunk. For allocated nodes we don't need to know the previous node, so we can use a union and use the entire chunk for user data. Allocations pop a node from the stack, deallocating pushes a node back to the stack.
template<size_t ChunkSize>
class PoolAllocator
{
struct Page
{
char memory[4096];
};
union Node
{
Node *previous;
char chunk[ChunkSize];
};
public:
PoolAllocator()
{
initPage(&m_page);
}
void *allocate(size_t size)
{
Q_ASSERT(size <= ChunkSize);
if (!stack)
return nullptr;
Node *top = stack;
stack = stack->previous;
return top->chunk;
}
void free(void *ptr)
{
Node *top = static_cast<Node*>(ptr);
top->previous = stack;
stack = top;
}
private:
void initPage(Page *page)
{
Node *newStack = reinterpret_cast<Node*>(page->memory);
newStack->previous = stack;
const size_t numChunks = sizeof(Page) / sizeof(Node);
for (size_t i = 0; i < numChunks - 1; ++i, ++newStack)
newStack[1].previous = newStack;
stack = newStack;
}
Node *stack = nullptr;
Page m_page;
};
This gives us O(1) complexity for allocations and deallocations, and practically 100% memory efficiency. All the allocator needs to store is a pointer to the top of the stack; for a 4K memory page this means 8 bytes of overhead on a 64bit system. That's pretty good! But so far our allocator can only operate on a fixed amount of memory.
Instead of being limited to a single page of memory, and returning nullptr when it's used up, we could allocate another page and add the chunks to the stack. That way, our pool of memory can grow as much as it needs to, and we don't have to worry about making the pool of memory large enough at compile time; we will still be able to allocate over a hundred 40-bit sized objects on a single 4K page of memory, and making one kernel roundtrip when we have to grow is quite ok. However, we now need to maintain a vector of pointers to memory pages so that we can free the pages when the allocator is destroyed.
template<size_t ChunkSize>
class PoolAllocator
{
struct Page
{
char memory[4096];
};
union Node
{
Node *previous;
char chunk[ChunkSize];
};
public:
PoolAllocator()
{
}
~PoolAllocator()
{
for (auto page : pages)
::free(page);
}
void *allocate(size_t size)
{
Q_ASSERT(size <= ChunkSize);
if (!stack && !grow())
return nullptr;
Node *top = stack;
stack = stack->previous;
return top->chunk;
}
void free(void *ptr)
{
Node *top = static_cast<Node*>(ptr);
top->previous = stack;
stack = top;
}
private:
bool grow()
{
Page *newPage = static_cast<Page*>(::malloc(sizeof(Page)));
if (!newPage)
return false;
initPage(newPage);
pages.append(newPage);
return true;
}
void initPage(Page *page)
{
Node *newStack = reinterpret_cast<Node*>(page->memory);
newStack->previous = stack;
const size_t numChunks = sizeof(Page) / sizeof(Node);
for (size_t i = 0; i < numChunks - 1; ++i, ++newStack)
newStack[1].previous = newStack;
stack = newStack;
}
Node *stack = nullptr;
QVector<Page*> pages;
};
Now the allocator can grow, one page at a time, to the needed size. Freeing pages that we no longer need... let's talk about that later ;)
Benchmarking
We now have a basic pool allocator in place, as a template class instantiated with the chunk size. This allows the compiler to generate very efficient code for us. So, how fast is it really? A trivial benchmark just allocates and frees memory in a loop. We want to optimize for small objects, so we will compare the speed for 16, 32, and 64 bytes of memory, and we are allocating 100, 200, and 400 blocks at a time, and then free those blocks in two loops, freeing first the odd and then the even indices. To get somewhat stable and comparable results, we run 250000 iterations.
void *pointers[allocations];
QBENCHMARK {
for (int i = 0; i < 250000; ++i) {
for (int j = 0; j < allocations; ++j)
pointers[j] = ::malloc(allocSize);
for (int j = 0; j < allocations; j += 2)
::free(pointers[j]);
for (int j = 1; j < allocations; j += 2)
::free(pointers[j]);
}
}
The allocators I compare are the default malloc implementations on our desktop platforms - macOS 10.14 (which is my development platform), Windows 10 with VC++17, and the system malloc on Linux (Ubuntu 18.04, which uses ptmalloc2). On Linux, I also compared with Google's tcmalloc, Microsoft's mimalloc, and jemalloc from FreeBSD and Firefox. It's trivial to use those allocators instead of glibc's malloc() on Linux, where they can just be LD_PRELOAD'ed.
$ LD_PRELOAD=LD_PRELOAD=/usr/local/lib/libtcmalloc.so ./tst_bench_allocator
These results are rather promising:
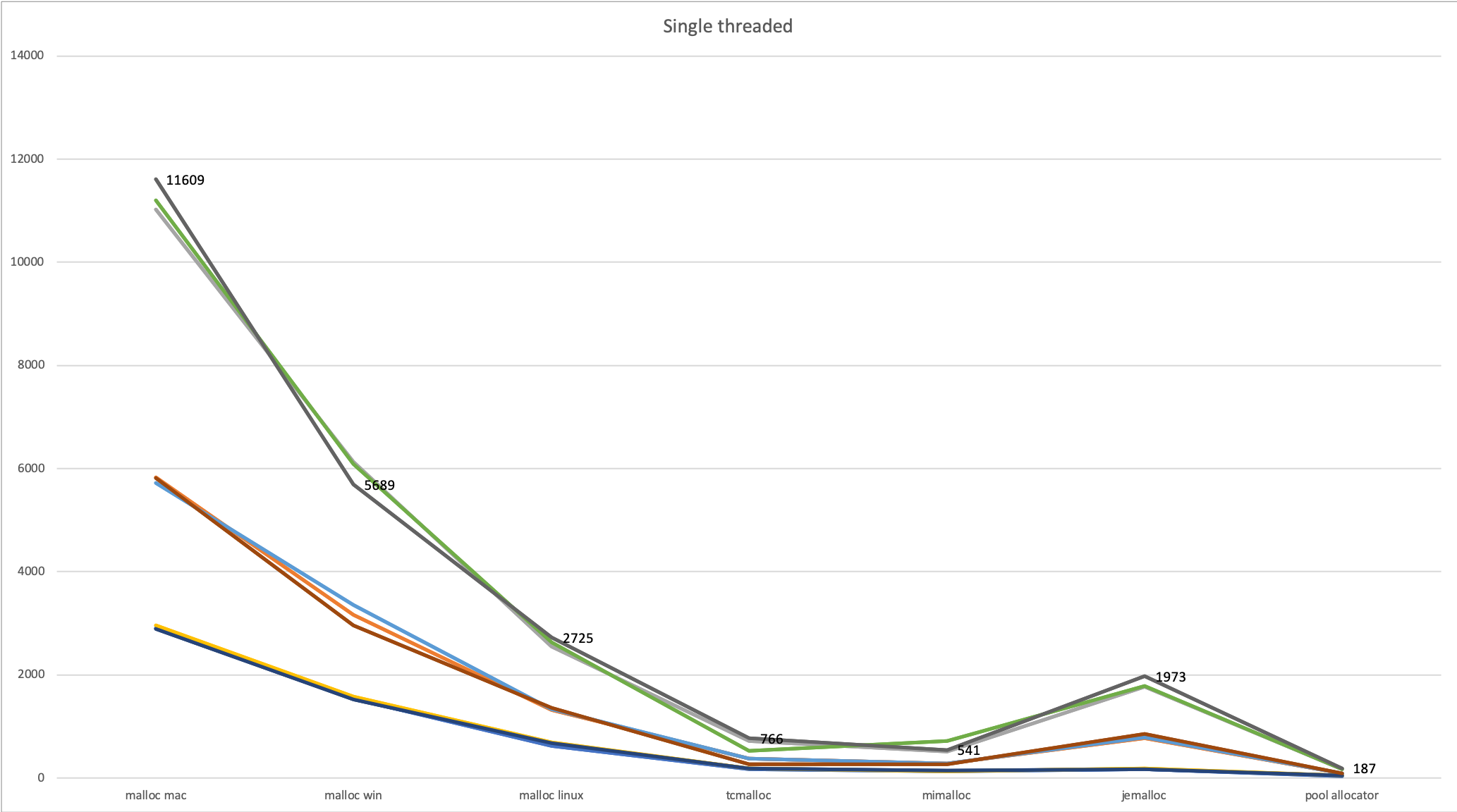
All allocators have rather stable behavior for our benchmark; the size of the allocated block barely makes a difference, and double the number of allocation takes twice as long.
Given the simplicity of our implementation, it shouldn't be surprising that our specialized pool allocator beats even the fastest general purpose allocators - a factor of 3 compared to mimalloc, and a factor of 70 compared to the system malloc on macOS 10.14.
This is rather promsing, even though we are also ignoring the big gorilla in the room: threads.
Threading Models
One of the use cases I want to design the allocator for is QEvent allocations in general, and QMetaCallEvent allocations in particular. QEvents can be created from multiple threads, so the allocator needs to be thread safe. What's more, we use QMetaCallEvent for cross-thread signal/slot emissions, and events can generally be posted to objects in different threads. So, the thread that allocates will not necessarily be the thread that frees the object, and the thread that allocated might even have terminated before the object is processed and deleted in the receiving thread.
But there will certainly be cases where client code can guarantee that the same thread that allocates memory is also the thread that deallocates that memory, or where everything is happening in a single thread (such as operating on a scene graph), and ideally we can make an optimized implementation for each of those situations, without duplicating all the code.
Locks
The options for making the allocator thread-safe are to introduce a lock, or to use a lock free stack implementation using atomic instructions. An atomic implementation would make the stack implementation itself lock-free, but it doesn't really help us with growing when we have depleted the stack. With a mutex however, look contention will be very high if multiple threads are trying to allocate and free memory.
We can reduce lock contention by allocating chunks from the free stack, but return chunks to a different "backlog" stack. We can then use a different mutex to protect the backlog; when we run out of free chunks, then we can swap in the backlog - for that operation we need to hold both mutexes.
void *allocate()
{
auto stack_guard = lock_stack();
// try to adopt backlog
if (!stack) {
auto backlog_guard = lock_backlog();
stack = backlog;
backlog = nullptr;
}
if (!stack && !grow())
return nullptr;
Node *top = stack;
stack = stack->previous;
return top->chunk;
}
void free(void *ptr)
{
auto guard = lock_backlog();
Node *top = static_cast<Node*>(ptr);
top->previous = backlog;
backlog = top;
}
This helps a bit, but running our benchmark with multiple threads quickly shows that this alone can't be a successful strategy.
Arenas
A more elaborate architecture would be to have each thread operate within its own "arena". Each thread needs to have its own pool of memory to work on, so we will have some overhead. We can use a thread_local variable for the thread-specific arena; the arena's lifetime is tied to the lifetime of the thread by way of using a std::unique_ptr.
private:
struct Arena
{
void push(void *ptr);
void *pop();
void grow();
void initPage();
QVector<page*> pages;
Node *stack = nullptr;
};
inline thread_local static std::unique_ptr<Arena> current_thread;
Arena *arena()
{
Arena *a = current_thread.get();
if (!a) {
a = new Arena;
current_thread.reset(a);
}
return a;
}
public:
void *allocate(size_t size)
{
Q_ASSERT(size <= ChunkSize);
Node *node = return arena()->pop();
return node ? node->chunk : nullptr;
}
void free(void *ptr)
{
Node *node = static_cast<Node*>(ptr);
arena()->push(node);
}
And as long as client code can guarantee that memory is freed by the same thread that allocated it, we don't need to use any locks to synchronise operations on the arena's stack.
If we combine the two approaches, then we end up with an allocator in which each thread pops chunks from its own arena, without any locking needed. Threads that free memory that came from another thread's arena will push the chunks to the original arena's backlog stack, so they only compete with other such freeing threads for the necessary lock. When the stack is depleted, the backlog is swapped in; only then does the allocating thread also need to compete for the lock. However, we need to be able to map a chunk of memory that client code passes into free() to the correct arena - we can't just use the thread_local arena pointer anymore, otherwise we end up with the freeing thread taking over all the memory from the allocating threads. Having a pointer to the arena for every chunk of memory on the stack would be one option, but introduces a fair bit of allocation overhead; having to write off 8 bytes for a chunk size of 40 bytes means that we waste 20% of memory.
Instead, we can make use of the fact that memory pages that we allocate using mmap() always have a 4K byte alignment. In the address of a page allocated with mmap (or VirtualAlloc on Windows), the lower 12 bits (4096 = 2^12) will always be zero, ie 0x123456789abcd000. The addresses of the chunks on the page will have the same upper 52 bit, so we can apply a simple bit mask to the address of a chunk, and we get the address of the page. We can then have a memory page hold a pointer to the arena that it belongs to, so we only have to sacrifice 8 bytes for each 4K page.
pivate:
struct Page
{
char memory[4096 - sizeof(Arena*)];
Arena *arena;
static Page *fromNode(Node *node)
{
return reinterpret_cast<Page*>(uintptr_t(node) & ~(sizeof(Page) - 1));
}
};
struct Arena
{
bool grow()
{
void *ptr = ::mmap(NULL, sizeof(Page), PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
Q_ASSERT_X(!(uintptr_t(ptr) % sizeof(Page)),
"PoolAllocator", "Page Alignment Error!");
if (!ptr)
return false;
Page *newPage = static_cast<Page*>(ptr);
initPage(newPage);
newPage->arena = this;
pages.append(newPage);
return true;
}
};
public:
void *allocate(size_t size)
{
Q_ASSERT(size <= ChunkSize);
Node *node = arena()->pop();
return node ? node->chunk : nullptr;
}
void free(void *ptr)
{
Node *node = static_cast<Node*>(ptr);
Arena *arena = Page::fromNode(node)->arena;
arena->push(node);
}
Extra complexity is added by the possibility that the allocating thread terminates while objects from its arena are still alive. For this, we need to decouple the life-time of the memory pool from the arena (which by way of the thread_local storage is coupled to the thread's lifetime); the allocator can take care of such stale memory pools; future threads will adopt them.
To implement this, we need to find out if there is still memory allocated, and our data structure doesn't know anything about allocated memory, only about free memory. So, the fastest way to check is to iterate over the entire stack, and count how many nodes we have. If it's fewer nodes than would fit on all the allocated pages, then memory is still in use.
Comparing the threading models
So now we have four threading models, with different trade-offs with regards to performance, memory overhead, and concurrency: single-threaded as the trivial case with a single arena, and no locks. A shared pool model where all threads operate in the same arena, with two locks. The multi-pool model where each thread has to stay within its own arena, but doesn't need any locks. Finally, the multi-threaded model where threads allocate from their own arena, but memory can be freed by any thread, and threads can terminate while memory allocated from their arena is still in use. The former three models will have a lot of use cases, but for our QEvent case we'll need the multi-threaded model.
Running our previous benchmark using those different implementations, but without using any threads, lets us measure the net overhead the various strategies introduce:
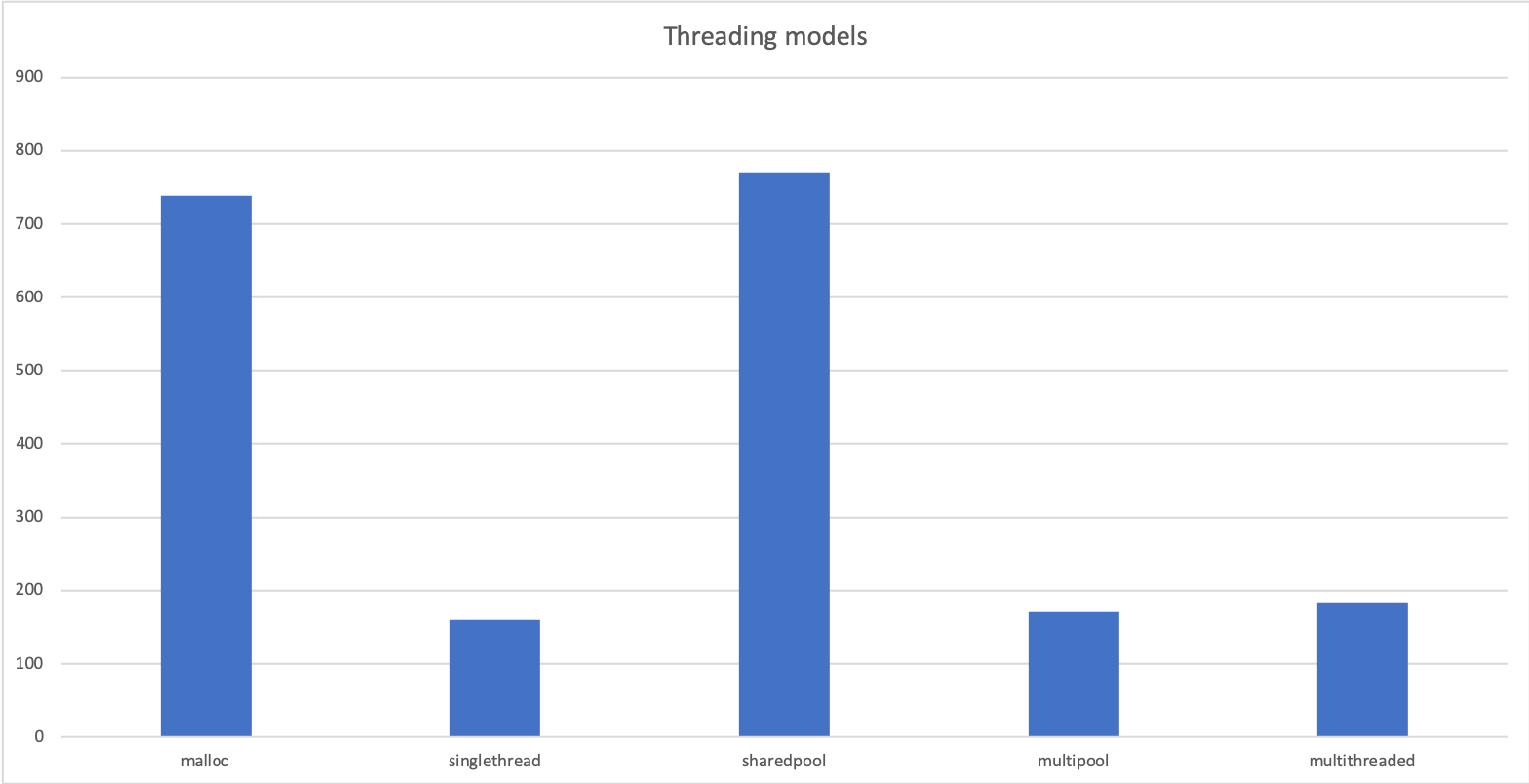
It seems that the extra-code needed to implement the arena-strategy introduces very little overhead. The shared-pool model on the other hand is not going to be of much advantage compared to just sticking with malloc, although it might still be worthwhile when considering memory fragmentation.
Multi-threaded Benchmarking
Benchmarking allocators in a realistic, multi-threaded scenario is not easy; even system malloc is very fast, so doing anything non-trivial besides allocating and freeing memory in the benchmark makes the real impact of the allocator hard to measure. However, if we only allocate and free memory, then the impact of lock contention in allocators becomes vastly exaggerated. On the other hand, we might have to use synchronisation primitives like mutexes or wait conditions to model the flow of data in a realistic producer/consumer scenarios (like when Qt uses QMetaCallEvent for signal/slot connections crossing threads). This will shadow the impact the locks in the allocator has.
Nevertheless, the relative numbers from should give us some indication on how efficient we are - an allocator that is significantly faster than others under stress is very likely to have some positive impact on the performance of a real world application. Based on the observation from our first benchmark that all allocators have similar performance characteristics no matter how big our small objects are, we now just run a single benchmark for 16 bytes objects, but with as many threads as we have CPUs.
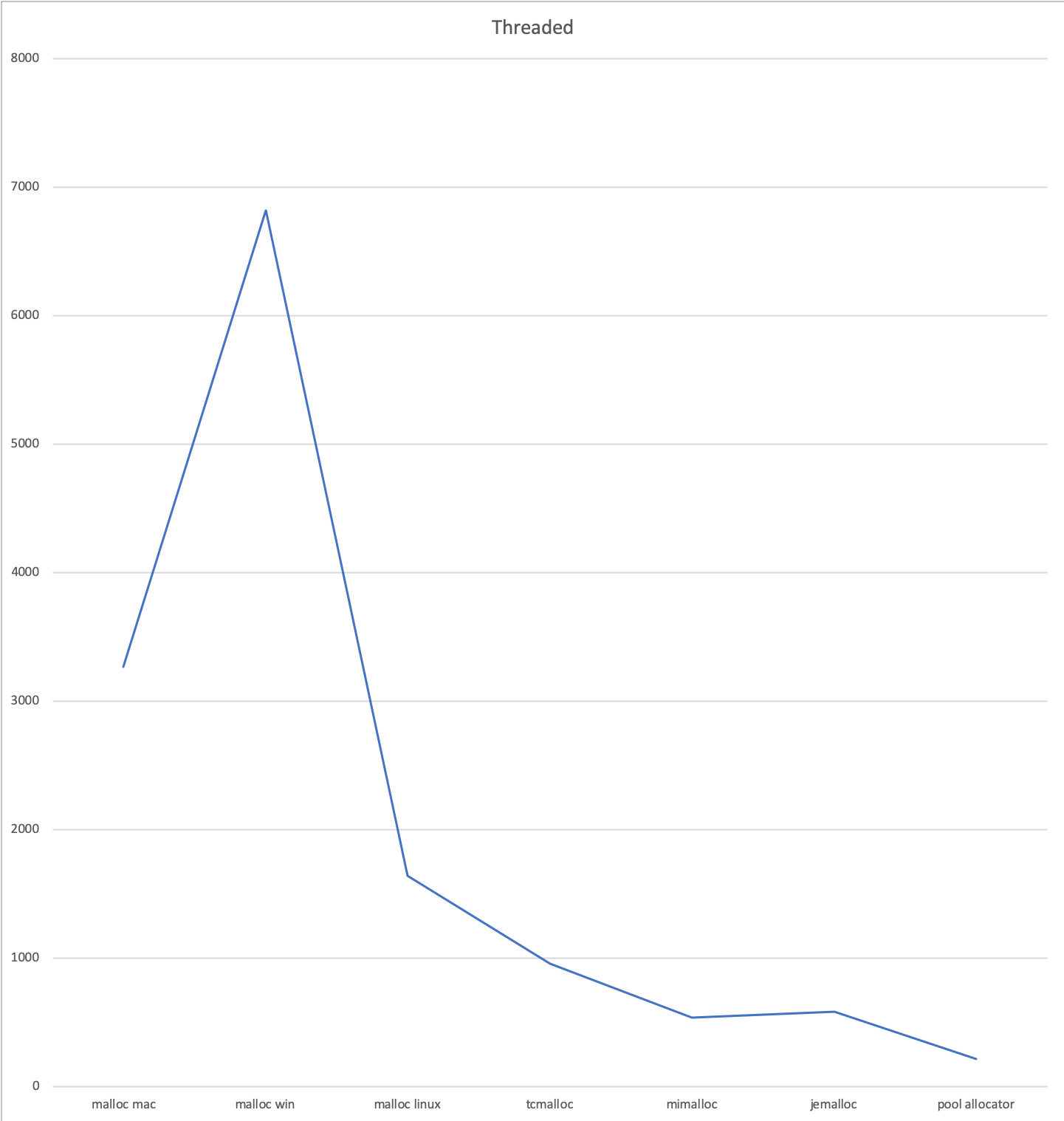
The threading model used here is the full multi-threaded implementation, with which our allocator still beats the fastest general purpose alternative by a factor of 2.5, and the default system mallocs consistently with a factor of at least 7.
In the next post, I'll look into testing and memory debugging techniques, and I'll show how we can use the ideas developed so far when allocating objects of different sizes. And maybe we find out how we can free empty pages as well...
Until then, I'm looking forward to your comments, and some thoughts on if and how you could use such an allocator in your project!


