2026年06月28日
Qt Canvas Painter をまだご存知でない方は、過去のブログ記事(はじめに、新機能、パフォーマンス測定)をぜひご参照ください。本記事では、パスとパスグループを活用してパフォーマンスをさらに向上させる方法をご紹介します。
ハードウェアアクセラレートレンダリングの一般的な通説として、命令型の描画は遅く、宣言型の描画は速いとされています。その基本的な理由は、GPU はデータを自ら保持することを得意とし、並列処理に優れているという点にあります。CPU から GPU へのデータ転送は、この並列処理においてボトルネックを引き起こす可能性があります。シーングラフ型のアプローチを用いた宣言型 UI は、UI のどの部分が実際に更新を必要としているかを追跡し、更新量を最小化することでパフォーマンスを向上させます。
この考え方は理にかなっていますが、命令型の描画は必ずしも遅くなるわけではない、というのが私の持論です。Vulkan や Metal などの低レベルグラフィックス API は命令型でありながら高速です。私はスクリーンに直接描画する場合に「ダイレクト」という言葉を好んで使います。「命令型」は、スクリーン以外のバッファへの描画にも使える言葉だからです。Qt Canvas Painter のダイレクト描画は極めて高速になるよう最適化されていますが、パスを管理するための QCanvasPath クラスも提供しています。
まず、次のようなカスタム折れ線グラフの描画という簡単な例から始めましょう。
QCanvasPainter を使って直接描画するコードは次のとおりです。
p->beginPath();
p->moveTo(data[0]);
for (int i = 1; i < 40; i++)
p->lineTo(data[i]);
p->setLineWidth(10);
p->setStrokeStyle(lineGradient);
p->stroke();
QCanvasPainter は非常に高性能であり、40 本の線分からなるグラフの描画も容易です。しかし、より複雑なパスを扱う場合や、毎フレームの再生成を避けたい場合はどうすればよいでしょうか?そこで登場するのが QCanvasPath です。QCanvasPath を使って同じ出力を得るコードは次のようになります。
if (m_path.isEmpty()) {
m_path.moveTo(data[0]);
for (int i = 1; i < 40; i++)
m_path.lineTo(data[i]);
}
p->setLineWidth(10);
p->setStrokeStyle(lineGradient);
p->stroke(m_path, 1);
このコードを見ると、いくつかの興味深い点があります。
- 描画コードが非常によく似ています。これは意図的な設計によるものです。QCanvasPath と QCanvasPainter がまったく同じ描画 API を持つことで、ダイレクト描画とパス描画の間でコードを容易に移植できます。
- パスが空になるのは最初のフレームだけなので、それ以降のフレームでは for ループをスキップして既存のパスをそのまま描画できます。
- stroke メソッドに謎めいた数値パラメータがあります。これはオプションのパスグループで、頂点バッファをキャッシュしてパフォーマンスをさらに向上させるためのものです。
パスアプローチのもう一つの利点として、次のような数行を追加するだけで同じパスを再利用しているため、わずかなオーバーヘッドでなめらかな影を追加できます。
...
p->setLineWidth(20);
p->setStrokeStyle(Qt::black);
p->setAntialias(10);
p->translate(-2, 4);
p->stroke(m_path, 1);
...
QCanvasPath vs. QPainterPath
Canvas Painter が既存の QPainterPath クラスを使わない理由を疑問に思う方もいるかもしれません。これはもっともな疑問であり、きちんと説明する価値があります。まず、Canvas Painter は QtGui のユーティリティクラス(QColor、QFont、QImage、QTransform、QRectF など)を多く活用しているため、単に差別化を図りたかったわけではありません。独自のパスクラスを設ける主な理由は 3 つあります。
- API の一貫性: QCanvasPath が QCanvasPainter とまったく同じパス描画 API を持つことは、使いやすさの観点から重要です。これにより、ダイレクト描画とパス描画の間でコードを容易に切り替えられます。また、HTML canvas の Path2D と一致する API を目指しています。
- データフォーマット: QCanvasPath は QPainterPath と比べて一般的に約 60% 少ないメモリしか消費しません。内部データフォーマットは CPU キャッシュにも優しい設計です(SoA vs. AoS)。パスのデータフォーマットが QCanvasPainter と完全に同一であるため、パスの add / fill / stroke は単純な memcpy として実装でき、非常に効率的です。
- キャッシュ: パスを完全に制御できるため、効果的なキャッシュ戦略も構築しやすくなります。パスが変更されない場合、データフォーマットが共有されているのでデータを直接活用できます。さらに、静的なパスを頂点バッファに保持する GPU 側のキャッシュも実装可能であり、再描画を非常に低コストな処理にできます。
QCanvasPath の基礎を理解したところで、パスグループとパフォーマンスへの影響について詳しく見ていきましょう。
パスグループ
QCanvasPath グループは、互いに関連するパスをまとめる方法です。これは HTML canvas 2d context が持たない新機能であり、QPainter および QPainterPath にも搭載されていません。Qt Canvas Painter は QRhi によってネイティブに HW アクセラレートされているため、この機能を実装することにしました。内部では 1 つのパスグループが 1 つの頂点バッファに対応するため、各グループには同時に更新が必要になることの多いパスをまとめるべきです。こうすることで、頂点バッファの数や各フレームで更新が必要な頂点の数を最適に抑えられます。
パスグループは stroke() および fill() メソッドに追加するオプションの整数パラメータです。その理由は以下のとおりです。
- HTML canvas 2d context API にできる限り近い API を維持するためです。これらのメソッドに対するオプションの追加パラメータであり、追加の最適化が必要な場合に使用できます。
- グループ分けの自由度を確保するためです。ニーズはアプリケーションによって大きく異なり、またアプリケーションのライフタイム中に変化することもあります。グループは C++ の enum として扱えるため、例えば STATIC_PATHS、DYNAMIC_PATHS、ICON_PATHS、SHARK_BACKGROUND_PATHS など、UI のニーズに合わせた名前を付けられます。
- 今後リリース予定の Canvas2D QML 要素とも良好に動作するためです。詳細は後ほどご紹介します。
Qt Canvas Painter は必要に応じてパスを自動的に無効化します。詳細なドキュメントがありますが、基本的にはストロークの線幅やキャップ/ジョインタイプの変更など、頂点の更新が必要になったときにパスを再生成する必要があります。そのため、最適なパフォーマンスを得るには、キャッシュされたパスに対してこれらの変更は避けることをお勧めします。一方、パスを無効化しない変更を把握しておくことも重要です。たとえば、パスに対するトランスフォーム(移動・回転・スケール)は GPU 側で処理されるため非常に高速です。また、塗りつぶし/ストロークのブラシを変更してもパスは無効化されないため、色やグラデーションのアニメーションも高速に処理できます。これを視覚的に確認できるのが、パステスターサンプルアプリを示した次の動画です。
動画からわかるとおり、線分の数が 100 万本に達すると、ダイレクト描画もキャッシュなしのパス描画も予想どおり遅くなり始めます。しかし、パスキャッシュを有効にすると、100 万本の線分でもスムーズにレンダリングされます。パスのトランスフォームやブラシのアニメーションは頂点バッファの更新を必要としないため、これらによるパフォーマンスの低下はありません。
プログレッシブレンダリング
毎フレーム変化しないパスは QCanvasPath を通じて描画することでパフォーマンスを向上できることがわかりました。しかし、常にアニメーションするパスを含む UI でも QCanvasPath は効果的です。特に組み込みデバイス向けの最適化においてはなおさらです。
ここでいうプログレッシブレンダリングとは、レンダリングの処理負荷を複数のフレームに分散させることで、全体的なパフォーマンスを向上させつつ CPU と GPU の消費を低減する手法です。一般的な 60Hz スクリーンでは、新しいフレームを表示するために 1 フレームあたり 16ms しかありません。この時間を超えると、スクリーンの同期フレームレートに達せずフレームがドロップされます。この問題の対策として、スクリーンのリフレッシュレートを例えば半分に下げることが考えられますが、UI の一部で 60Hz のフルアニメーションが必要な場合には最適な解決策とはいえません。
Qt Quick がプログレッシブレンダリングのために提供する一般的な手法として、アイテムレイヤーの使用があります。たとえば、FrameAnimation を使用して奇数/偶数フレームごとに個別のフレームを live にする方法です。これにはアニメーションの手動調整とレイヤーテクスチャのキャッシュが必要ですが、有効なアプローチです。QCanvasPainterItem では、アイテムが暗黙的にテクスチャによってバックされているためさらに簡単で、コンテンツを実際に更新する必要があるときにのみ update() を呼び出すだけで済みます。ただし、これらのアプローチが有効なのはアイテム全体をプログレッシブにレンダリングしたい場合に限られます。アイテムの一部を常時更新しながら他の部分をより低い頻度で更新したい場合には対応できません。
QCanvasPath とパスグループは、レイヤーテクスチャではなくパスの頂点バッファをキャッシュするという、プログレッシブレンダリングの別のアプローチを提供します。これにより、アイテムの一部だけをキャッシュするという細かい制御が可能になります。医療・産業用途に対応しうるサンプル UI で評価してみましょう。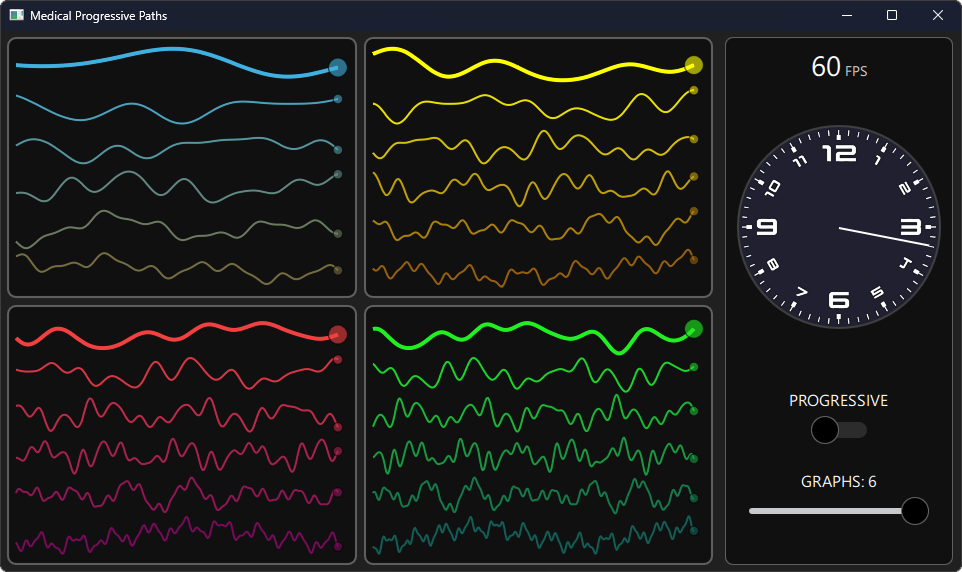
この UI には 4 つのグラフコンポーネントがあり、それぞれに複数のリアルタイムプロット折れ線グラフが含まれています。対象ハードウェアは、すべてのグラフを完全なスクリーンリフレッシュレートでレンダリングする能力がない組み込みデバイスを想定しています。しかし、この UI には画面右側に高い精度が必要なタイマーコンポーネントも含まれており、フルスピードで更新する必要があります。太めのメイングラフもフルスピードで更新する必要がありますが、細いグラフはそれほど頻繁に更新する必要はありません。センサーやデータベースからのデータ取得がそれほど速くない場合もあるため、1 秒間に 15 回(15Hz)の更新で十分なこともあります。また、バッテリー寿命を延ばすために CPU と GPU の負荷を抑えることも目標です。
これを実現するために、QCanvasPath を使用してグラフアイテムごとに専用のパスグループへ描画します。そして、次のようなコードで 1 フレームごとに 1 つのグラフだけを更新します。
...
m_frame++;
m_update = (m_frame % 4 == m_graphIndex);
if (m_update) {
m_path.clear();
.. recreate the graph ..
}
...
このシンプルな変更によって、プログレッシブレンダリングを有効にすると、CPU と GPU の使用率を低減しながら全体で安定した 60fps を達成できます。以下の動画は、低スペックの Android タブレット(Lenovo Tab M10 HD、Mediatek MT6762 + PowerVR GE8320)での動作を示しています。
まとめ
Qt Canvas Painter をまだ試していない方は、ぜひ一度試してみてください。Qt 6.12.0 Beta 1 が先日リリースされました。Qt Canvas Painter は Qt 6.12 で正式サポートモジュールに昇格する予定であり、今のうちにテストしてフィードバックをお送りいただくことが非常に有益です。また、Qt 6.12 には新しい Canvas2D QML 要素も搭載される予定で、QML JavaScript から Canvas Painter のスムーズさを利用できるようになります。詳細は後ほどお伝えします。それでは、楽しいハッキングと素晴らしい夏をお過ごしください!


