2026年06月23日
コメント
このブログは「Qt Creator 20 and local AI」の抄訳です。
Qt Creator 20 は Agent Client Protocol(ACP)クライアント拡張機能となりました。このプロトコルは多くの AI プロバイダーがサポートしており、AI コーディングエージェントと IDE 間の通信の詳細を処理します。
ACP Registry では、Claude Agent、Codex CLI、Gemini CLI、GitHub Copilot などの ACP エージェントを確認できます。
これらの ACP エージェントはそれぞれのクラウド AI サービスと通信するため、サブスクリプションが必要です。
本記事では、既存のハードウェア上でローカル AI を動作させる方法をご紹介します。
ハードウェア環境
テスト環境は 2023 年モデルの 14 インチ MacBook Pro M3(RAM 36GB)です。ebay.de では €1,700〜2,300 で出品されています。
RAM 36GB であることは重要です。32GB ではフルコンテキストでの実行には不十分でした。以下は、pi ACP エージェントで Qt Creator を起動したときのラップトップの様子です。メモリ使用率は 88% で、Microsoft Teams などの Electron アプリや Web ブラウザは起動していない状態です。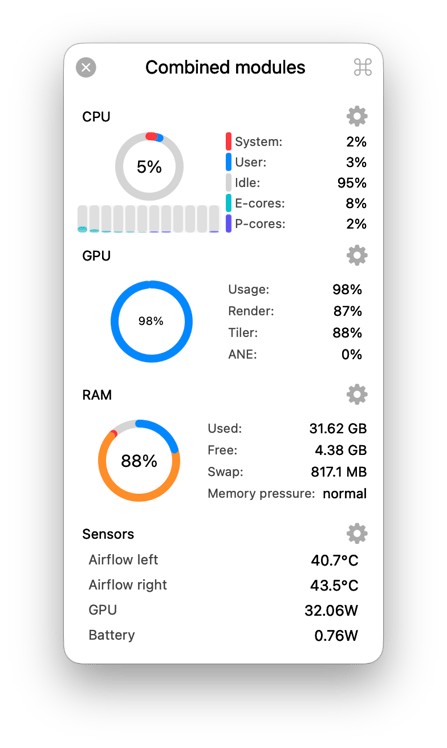
ローカル AI モデル
2025 年 8 月、OpenAI は gpt-oss モデルをリリースしました。
gpt-oss-120b と gpt-oss-20b をリリースします。低コストで実世界の高いパフォーマンスを発揮する、最先端のオープンウェイト言語モデル 2 種です。柔軟な Apache 2.0 ライセンスで提供されており、推論タスクにおいて同規模のオープンモデルを上回り、強力なツール利用能力を備え、コンシューマーハードウェアへの効率的なデプロイに最適化されています。
128K コンテキストを持つ gpt-oss-20b が私の第一候補でした。このラップトップで「Hello World」プロンプトを実行すると、40〜45 トークン/秒で回答が得られました。
2026 年 4 月、Google が Gemma 4 モデルをリリースしました。ライセンスも Apache 2.0 で、コンテキストサイズは最大 256K と gpt-oss-20b の 2 倍です。
候補として考えていたモデルは gemma-4-26B-A4B-it です。gpt-oss-20b との比較では、コンテキストが 2 倍になっただけでなく、マルチモーダルにも対応しており、テキストと画像の両方を入力として扱えます。
その後、Google は以下のアップデートを公開しました:
- 2026 年 5 月:Accelerating Gemma 4: faster inference with multi-token prediction drafters
- 2026 年 6 月:Gemma 4 QAT models: Optimizing model compression for mobile and laptop efficiency
これら 2 つの最適化により、gemma-4-26B-A4B-it-qat では「Hello World」プロンプトへの応答が 55 トークン/秒に達します!
ローカル AI ソフトウェア
llama.cpp を Homebrew でインストールし、unsloth/gemma-4/qat モデルで以下のように起動しました。
#!/bin/sh
llama-server \
-hf unsloth/gemma-4-26B-A4B-it-qat-GGUF:UD-Q4_K_XL \
--spec-type draft-mtp --spec-draft-n-max 2 \
--reasoning off 今回のタスク
Qt Blog: Introducing Qt Agentic Development Skills から、renderarea.cpp ソースコードを使った qt-cpp-docs スキルのタスクを選択しました。
opencode ACP エージェント
最初に opencode.ai の ACP エージェントを試しました。TheQtCompanyRnD/agent-skills の設定は次のとおりです。
$ ln -s ~/Projects/qt.io/agent-skills/skills ~/.config/opencode/skillsopencode.json の内容:
{ "$schema": "https://opencode.ai/config.json", "provider": { "llama-cpp": { "npm": "@ai-sdk/openai-compatible", "name": "llama.cpp server", "options": { "baseURL": "http://127.0.0.1:8080/v1" }, "models": { "default": { "name": "Default Model" } } } }, "model": "llama-cpp/default" }
以下は Qt Creator 20 と opencode ACP エージェントを使用した録画です。
pi ACP エージェント
次に、ACP アダプター経由で pi.dev を試しました。TheQtCompanyRnD/agent-skills の設定も同様に行いました。
$ ln -s ~/Projects/qt.io/agent-skills/skills ~/.pi/agent/skills以下は Qt Creator 20 と pi ACP エージェントを使用した録画です。
スキルの手動実行
最後に、llama.cpp の Web インターフェースを直接使用し、スキルとソースファイルを含む同じプロンプトを入力しました。
録画は以下をご覧ください。
まとめ
上記の実行結果を以下の表にまとめます。
| ACPエージェント | 時間 (mm:ss) | 消費電力 (Wh) | 利便性 | 結果 |
|---|---|---|---|---|
| opencode | 2:00 | 1.80 | ✅ | renderarea.md |
| pi | 1:02 | 0.89 | ✅ | renderarea.md |
| none | 0:27 | 0.66 | ❌ | renderarea.md |
スキルに適切なソースファイルをコンテキストとして直接渡す方法が最速で、消費エネルギーも最小でした。ただし、Markdown ファイルの手動作成や、スキルとコンテキストソースファイルを含むプロンプトの準備が必要となるため、利便性では劣ります。
opencode ACP エージェントが pi ACP エージェントの 2 倍の時間を要した理由は不明です。原因究明の第一歩は、llama-server の詳細ログを有効にすることです。これにより、ローカル AI へのすべての通信をトレースできます。
ローカル AI ではトークンに対する課金は発生しませんが、エネルギーと時間というコストがかかります。ただし、Apple Silicon 搭載コンピューターでは、プラットフォームの効率性によりエネルギーコストを抑えられます。
皆様の ACP エージェントはこのタスクをどのくらいの速さでこなしますか?ぜひコメント欄にお寄せください。また、AI クラウドプロバイダーが推論の際に消費しているエネルギーや水の量はご存知でしょうか?


