2026年07月2日
著者: Otso Virtanen、James Vance
テストケース生成におけるコンテキストの課題
テスト生成は、AIコーディングエージェントの実用的な使用例として最も一般的なものの一つです。しかし、実行時のコードカバレッジデータがない場合、テストの不足箇所を判断するAIコーディングエージェントは、ソースファイルとテストファイルを静的に解析してカバー範囲を推測するしかありません。この方法は信頼性が低く、複数の層を経て間接的に呼び出される関数と、まったく到達しないコードとを区別できず、デッドコードも確実には検出できません。
Coco のようなコードカバレッジソリューションは、実際のテスト実行から得られる、計測ポイント単位の正確な実行データをコンテキストとしてエージェントに提供します。Coco を繰り返し呼び出すことで、探索空間内でカバレッジ目標に向けてテストコード生成ワークフローを導くフィードバックループを構築できます。
本ブログシリーズの第1回(Part 1)では、Coco CLI ツールを活用してコードカバレッジを最大化する単体テスト生成タスクにおいて、このワークフローを実装しました。この度、開発者、テスター、マネージャー、そしてCI/CDで活用できる、生成AIを活用したワークフロー向けの Coco MCP Server Preview をリリースします。
Coco MCP Server のご紹介
Coco MCP server は、Coco コマンドラインインターフェース(CLI)ツールを構造化されたインターフェースでラップした Model Context Protocol(MCP)サーバーです。エージェントは cmreport や cmcsexeimport を直接呼び出して出力を解析する代わりに、MCP server 内の専用ツールを呼び出すことで構造化データを取得でき、効率的に処理しつつコンテキストウィンドウを圧迫しません。
MCP はAIコーディングエージェントを外部ツールやデータソースに接続するための、事実上の業界標準です。VS Code の GitHub Copilot や Claude Code を含め、主要なAIコーディングエージェントはすべてこのプロトコルをサポートし、MCPホストとして動作します。そのため Coco MCP server は、ワークフローのプロンプトを変更することなく、すべてのMCPホストで利用できます。以下の図が構成を示しています。
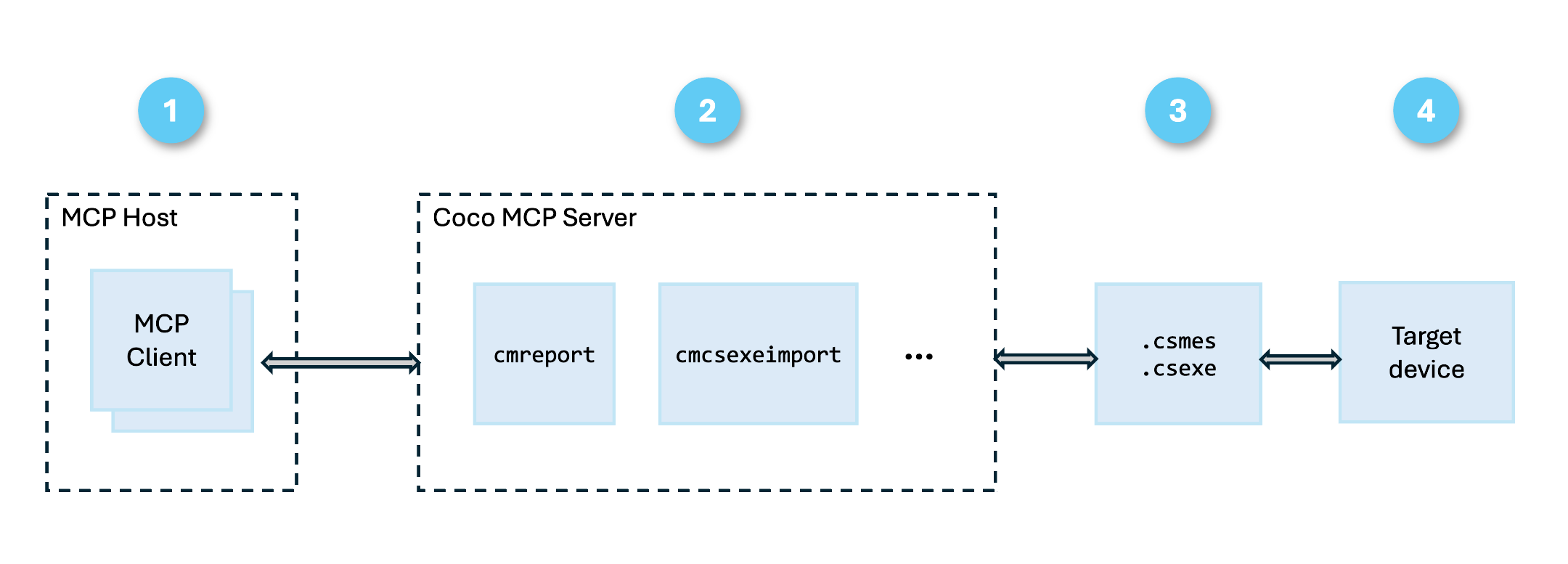
Coco MCP server には、以下の利点があります。
- トークン効率
カバレッジサマリーから不要なフィールドを除去し、レポート全体をコンテキストウィンドウに読み込む代わりにカバレッジレポートのセクションをストリーミングすることで、必要なトークン数とコンテキストを削減します。また、Coco MCP server は段階的開示によってカバレッジデータを提供するため、AIコーディングエージェントは最初は最小限の有用な情報のみを受け取り、必要に応じてより的確で詳細な情報を取得できます。 - CLI ツールの利用が容易
Coco CLI のフラグは扱いが煩雑になりがちですが、その複雑さはMCPツール呼び出しの内部に隠蔽されます。 - 内蔵ワークフロー
Coco MCP Server には、コードカバレッジを利用する際にどのみち定義が必要となるワークフローがあらかじめ組み込まれています。
上記の利点は特に大規模プロジェクトで有効だと考えられます。小規模プロジェクトであれば、AIコードエージェントが Coco CLI ツールを直接利用する方法でも十分に機能するでしょう。
Coco MCP server が提供するツール
前述の通り、このツールセットは、エージェントがその時点の判断に必要な分だけデータを取得できるように構成されています。これにより、レスポンスが小さく保たれ、エージェントのコンテキストウィンドウも本来の作業に集中できます。
check_coverage_summary
cmreport を呼び出し、単一のブール値を返す軽量なサニティチェックです。false の場合、データベースに実行結果が存在しないため、以降のレポート呼び出しは空のデータを返します。その場合、エージェントは先に import_execution_report を呼び出す必要があります。
import_execution_report
cmcsexeimport によって、.csexe 実行レポートを .csmes データベースにマージします。この呼び出し後、以降のすべてのツールでカバレッジデータが利用可能になります。
get_coverage_overview
グローバルなカバレッジ率、ファイル単位の内訳、そして任意で関数単位の内訳を返します。これにより、エージェントは調査すべきファイルや関数を特定できます。エージェントはこの情報を使って優先順位を付けるため、すべてのファイルを詳細に確認する必要がありません。
出力例(デシジョンカバレッジ、parser サンプル)
|
File |
Coverage |
Decisions |
Complexity |
|
parser.cpp |
47.6% |
137/288 |
121 |
|
error.cpp |
25.0% |
9/36 |
19 |
|
variablelist.cpp |
47.1% |
8/17 |
11 |
|
functions.cpp |
0.0% |
0/17 |
7 |
|
parser.h |
100% |
9/9 |
7 |
|
error.h |
100% |
4/4 |
4 |
|
Global |
45.0% |
167/371 |
— |
get_file_coverage_detail
カバレッジ状態(unexecuted、dead-code、executed)ごとにグループ化した、正確なファイル:行の位置情報を返します。エージェントはこれを使って、新しいテストで対象とすべき行を正確に特定でき、ソースファイル全体を読んで不足箇所を推測する必要がなくなります。
status_filter を使うと、エージェントが対処すべきステータス(通常は ["unexecuted"])のみにレスポンスを絞り込めます。大規模なコードベースでは、実行済みの行が大半を占め、実用的な情報が埋もれてしまうためです。
include_tests=True を指定すると、各計測ポイントを実行したテスト名の一覧もレスポンスに含まれます。これは、特定のコードを変更する前に既存のテストカバレッジを把握したい場合や、変更後に実行すべきテストを判断したい場合に有用です。
analyze_patch_coverage / analyze_patch_coverage_from_diff
このツールは、Coco のパッチ分析機能を提供します。統一 diff を渡すと、変更された行をカバーする既存テストの一覧と、その現在の成功/失敗状態を返します。エージェントはこれを使って、コード変更後にリスクのあるテストを判断でき、フルスイートの実行ではなく的を絞った再実行が可能になります。 パッチファイルのパスまたはインラインの diff 文字列のいずれかを受け付けるため、中間ファイルを作成せずに git diff の出力から直接呼び出せます。
ワークフロー例
以下は、Coco parser サンプルに対して Coco MCP server を利用するAIコーディングエージェントとのセッション例です。
プロンプト: 「parser サンプルをビルドし、現在のデシジョンカバレッジを分析して」
| ステップ | MCP ツール | 結果 |
| ソースと既存テストの確認 | - | 構造理解のため parser.cpp、unittests.cpp を読み込み |
| 未実行行の特定 | get_file_coverage_detail(status_filter: unexecuted、file: parser.cpp) | 151件の未実行計測ポイントを特定 |
| 対象を絞ったテストの作成 | - | ビット演算、比較演算、算術演算、数学関数、三角関数の演算子に対する新規テストケースを追加 |
| 計測済みバイナリの再ビルド | - | 更新された unittests.exe.csexe を生成 |
| 更新結果のマージ | import_execution_report | 新しい実行データをマージ |
| 改善の確認 | get_coverage_overview(decision、global + source-tree) | parser.cpp 47.6% → 88.9%;グローバル 45.0% → 80.1% |
今後の予定
今後も Coco の機能を MCP server に追加・拡張していきます。次の候補としては、Change Risk Anti-Patterns(CRAP)メトリクス、Python のサポート、agent skills の統合、そして QML のコードカバレッジが挙げられます。
詳しく知りたい方へ
Coco に関する詳細は、製品ページおよび製品ドキュメントをご覧ください。Qt 開発者の方は、QML の例およびQt の手順もご参照ください。
日本国内のお問い合わせは japan@qt.io 宛にご連絡ください。

